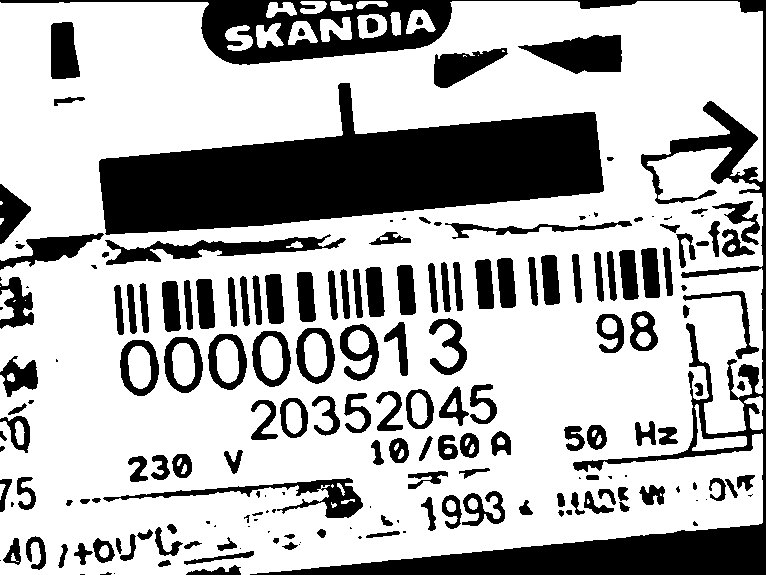|
|

|
Introduction
We describe an optical character recognition (OCR) system intended for
use in industrial applications. It was primarily designed for reading of
serial numbers of electricity meters. It is appropriate for use in a wide
range of industrial OCR applications such as reading of various types of
serial numbers and notes on packing material. With some modifications it
could also be used for other purposes such as reading of car licence plates.
Because of it's industrial orientation there is a special focus on reliability
and robustness.
Problem description
There are two problems that must be solved. Character segmentation and
character recognition.
Character segmentation is used to locate individual characters and
find their correct order according to position of individual strings in
the image and position of character in the string. Determination of location
consists of determination of translation and determination of rotation
and this must be done irrespective to all other objects in the image.
Character recognition is used to determine the relation between images
of individual characters and symbols they represent (characters). There
is a lot of different methods for character recognition, but thy are not
all suitable for industiral applications. Experiment results show that
some methods widely used in non-industrial OCR applications are less appropriate
for industrial use. The problem is in demanded reliability and robustness.
Implemented methods must allow some defect of characters but they must
also be able to distinguish characters from other objects.
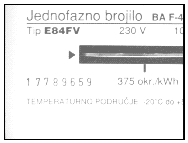
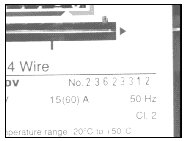
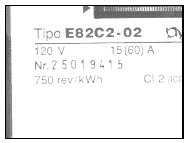

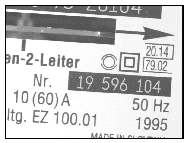

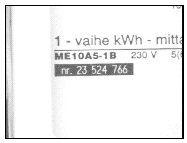

Figure 1: Diferent types of electricity meter serial numbers
Implementation
The overall process consists of five processing steps:
- image acquisition,
- preprocessing,
- character segmentation,
- character recognition and
- postprocessing.
Image acquisition
Image is acquired using a Sony
XC-75 grayscale camera and a Matrox
Meteor frame grabber. The size of characters on acquired image must
not be less than 20 pixels. In case of smaller characters the appropriate
recognition reliability cannot be achieved.

Figure 2: An example of acquired image (click to enlarge)
Preprocessing
reprocessing consists of image sharpening,
normalization,
filtering and
binarization.
Sharpening is used quite rare, because it increases noise, but it gives
better results at unfocused images. With use of normalization better results
are achieved at binarization stage. Filtering is very important if there
is a bad lightening (blinking light) and interlaced camera is used. There
are three methods of binarization implemented in the system. These
are manual threshold selection, automatic thresholding and automatic local
thresholding. Methods used in preprocessing can be selected according to
the operating environment.

Figure 3: Result of preprocessing step (click to enlarge)
Character segmentation
Character segmentation consists of two steps. In the first step individual
strings are located and their correct order according to the position in
the image is found. In the second step every string located in the previous
step is segmented into individual characters. There is a special focus
on broken and connected characters.

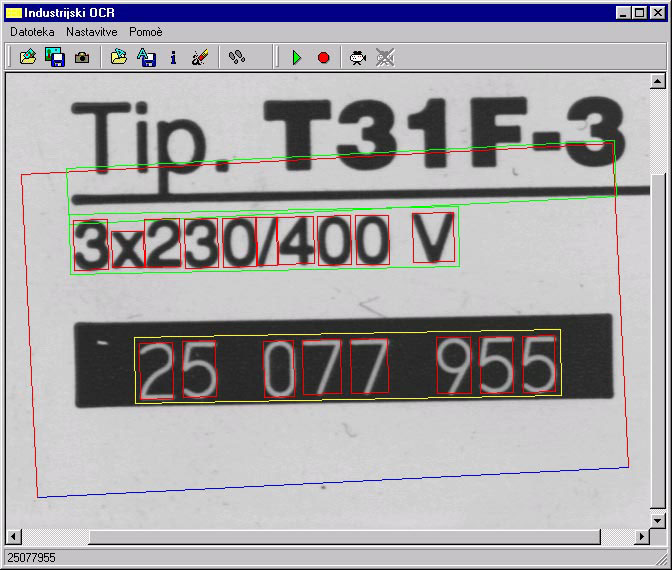
Figure 4: Results of segmentation. Marked areas represent strings
(green and yellow) and characters (red).

Figure 5: Segmentation of broken characters (right image)
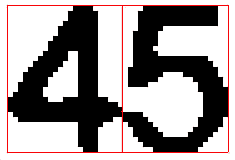
Figure 6: Segmentation of connected characters
Character recognition
Character recognition methods used in the system are not font invariant
so learning stage is required before recognition. Recognition is based
on classification. For that purpose every class (every kind of character)
is represented with a reference character. Reference characters are charactes
used in learning stage. Classification is preformed according to the calculated
distances between recognizing character and all the reference characters.
If distances do not correspond to some predefined conditions, recognizing
character is marked as unrecognized.
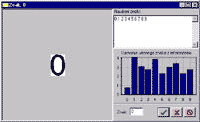
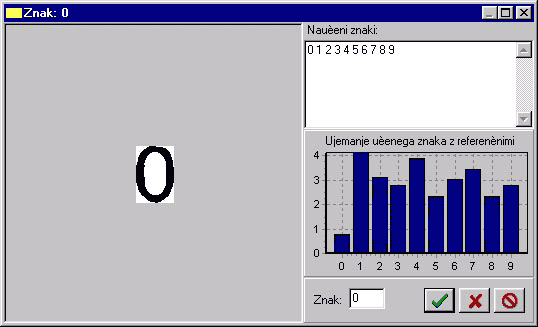
Figure 7: Window of the learning stage (click to enlarge)
Postprocessing
There is always just one string that needs to be recognized. In the postprocessing
step it has to be determined wich is the right one. Determination is accomplished
regarding to the following presets:
- number of characters in a string,
- position of a string,
- recommended first character,
- recommended last character and
- list of restricted characters.
It is not need to use all the stated presets.
Another very important task of postprocessing step is warning in case
of unsuccesful recognition. The recognition is stated as unsuccesful if
there are unrecognized characters in the resulting string or if the resulting
string does not match with all the requested presets.
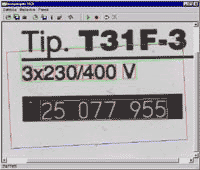
Figures 8: Appearance of the main program window (click to enlarge)
Conclusions
Experiment results confirms the selection of methods and suitability of
the system for industrial use. We have also implemented a voice controlled
user interface, which simplify the interventions at unsuccesful recognition.
As the computer is often not located near the process makes possible to
controll the process or correct the uncuccesful recognition with voice.
Although the unsuccesful recognition si very rare and is supposed to happen
only at bad conditions at image acquistion or when the interested string
is damaged the user interface is simple and user friendly.
Publications:
P. Rogelj, S. Kovačič,
"Odcitavanje serijske stevilke elektricnih stevcev", ERK '98, September 1998.
|
|
P. Rogelj, S. Kovačič,
"Odcitavanje serijske stevilke elektricnih stevcev", diploma theesis, July 1998.
|
|
P. Rogelj, S. Dobrisek, F. Mihelic,
"Govorni uporabniski vmesnik v industrijskem okolju", ERK '99, September 1999.
|

|
|